Learning Vector Quantization
Post en español
Teoría
Learning Vector Quantization (LVQ) es un algoritmo de clasificación supervisada basado en prototipos, que busca representar cada clase mediante vectores representativos (‘prototipos’) que se ajustan iterativamente a los datos.
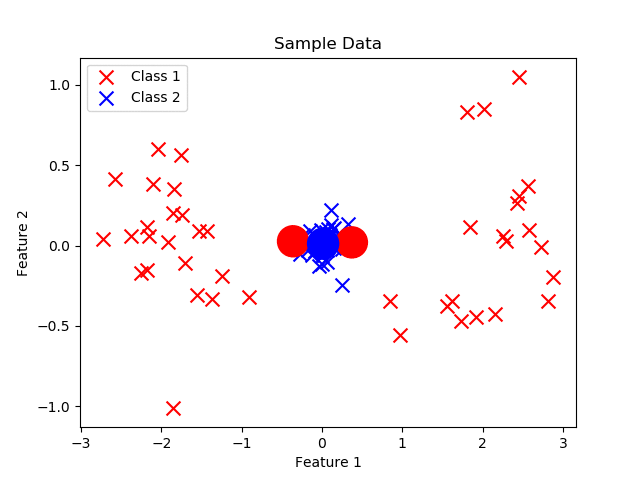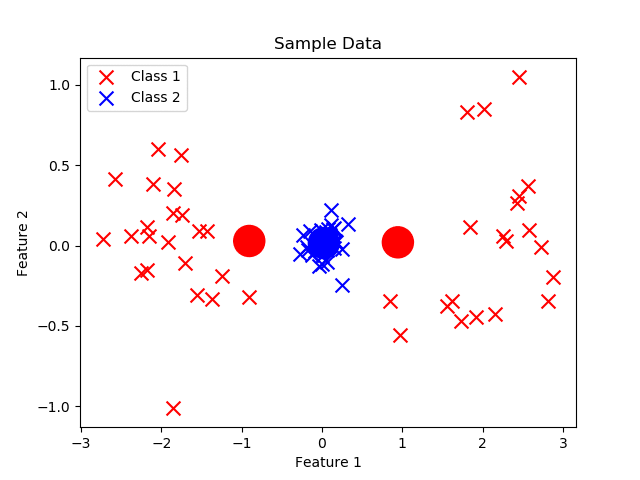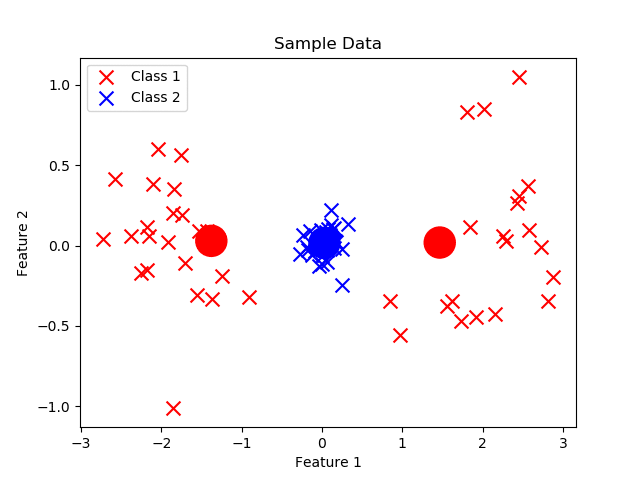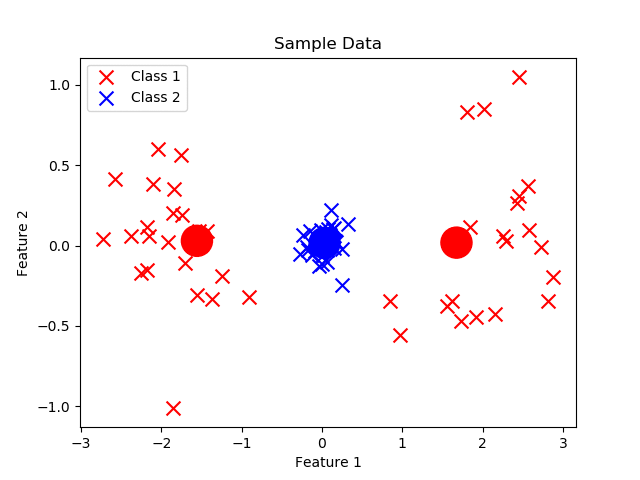
Los prototipos son como imanes: se acercan a los datos de su propia clase y se alejan de los de clases diferentes.
El procedimiento de aprendizaje del LVQ puede resumirse de la siguiente manera:
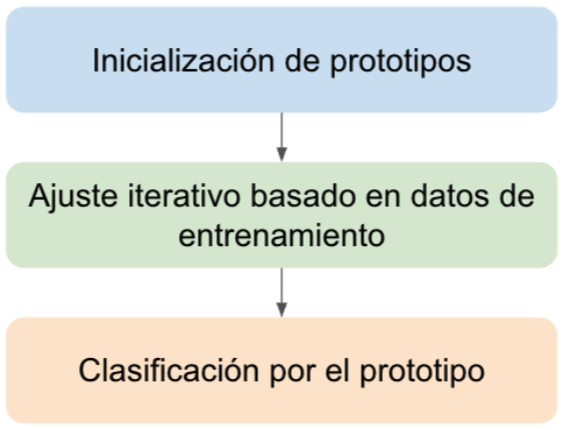
Podemos pensar en los prototipos como algo similar a los centroides que se presentan en KMeans. Sin embargo, el ajuste iterativo es diferente. A diferencia de KMeans, que es un algoritmo no supervisado, LVQ es supervisado, ya que el ajuste de los prototipos depende no solo de la distancia, sino también de la clase de cada ejemplo.
Viendo el procesamiento a detalle tenemos lo siguiente:
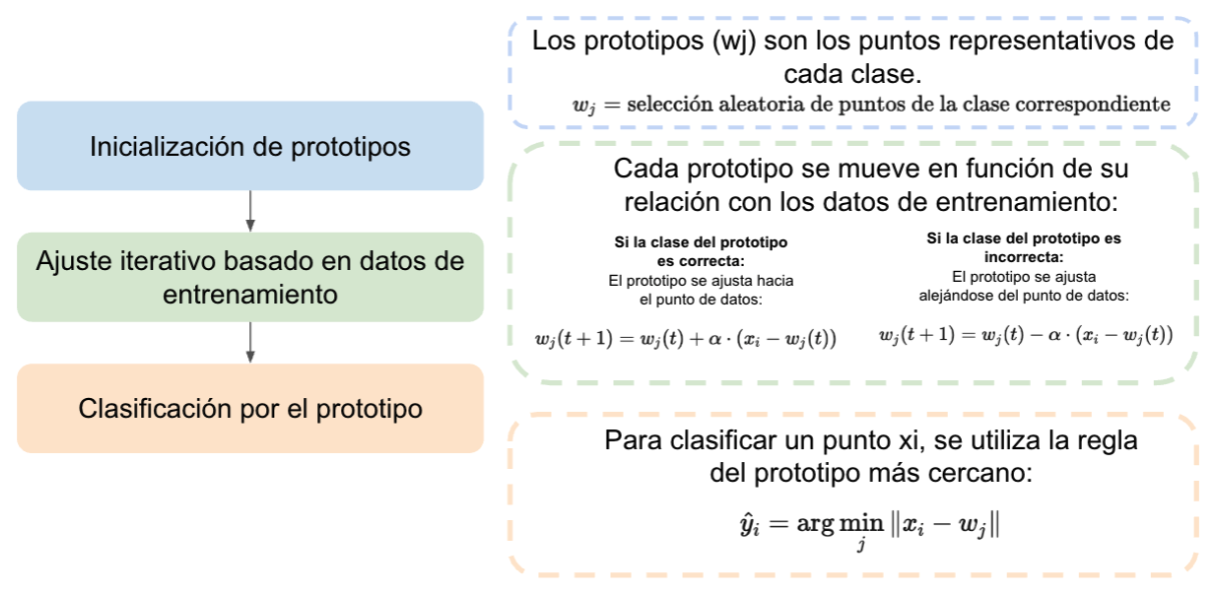
Añadiendo información a los procesos de LVQ tenemos:
- Inicialización de prototipos: Importante mencionar que el numero de prototipos es respecto al número de clases. La inicialización de protitpos puede realizarse con valores aleatorios, o tambien copiando un valor aleatorio de los registros presentes en el dataset.
- Ajuste iterativo basado en datos de entrenamiento: En este proceso se evidencia la clara diferencia con respecto a KMeans. Primero se debe calcular la distancia de un registro i con respecto a cada prototipo. Esta distancia puede ser euclidiana, manhattan, etc. Posteriormente nos enfocamos en el prototipo más cercano a dicho registro i. Si el prototipo más cercano es de la misma clase que el registro i se actualiza el valor del prototipo (w) con la siguiente formula:
En otras palabras acercamos al prototipo al registro i, porque son la misma clase. Por otro lado, si el prototipo mas cercano es de una clase diferente al registro i se actualiza el prototipo (w) para alejar al prototipo:
\[w(t+1) = w(t) - \alpha \cdot \bigl( x - w(t) \bigr)\]- Clasificación por el prototipo: En la fase de clasificación, un nuevo registro es asignado a la clase de su prototipo más cercano, funcionando de manera similar a un clasificador k-NN, pero utilizando solo los prototipos como referencia.
Código
La implementación de LVQ se puede realizar de la siguiente manera:
1) Generamos un dataset sintético:
import numpy as np
np.random.seed(42)
class1 = np.random.randn(50, 2) + [2, 2]
class2 = np.random.randn(50, 2) + [6, 6]
data = np.vstack((class1, class2))
labels = np.array([0] * 50 + [1] * 50)2) Definimos el modelo:
Inicializamos los parámetros necesarios para el funcionamiento de LVQ:
n_classes = 2
learning_rate = 0.1
n_iterations = 100 En este caso inicializamos los prototipos basandonos en una elección randómica en nuestro dataset:
prototypes = np.array([data[labels == i][np.random.choice(len(data[labels == i]))] for i in range(n_classes)])Definimos la distancia para el ajuste de los prototipos, en este caso la distancia euclideana:
def euclidean_distance(a, b):
return np.sqrt(np.sum((a - b) ** 2))Ahora definimos LVQ con numpy:
for iteration in range(n_iterations):
for i in range(len(data)):
x = data[i]
y = labels[i]
distances = np.array([euclidean_distance(x, prototype) for prototype in prototypes])
closest_prototype_idx = np.argmin(distances)
if closest_prototype_idx == y:
prototypes[closest_prototype_idx] = prototypes[closest_prototype_idx] + learning_rate * (x - prototypes[closest_prototype_idx])
else:
prototypes[closest_prototype_idx] = prototypes[closest_prototype_idx] - learning_rate * (x - prototypes[closest_prototype_idx])3) Definimos la función de clasificación:
def classify(x, prototypes):
distances = np.array([euclidean_distance(x, prototype) for prototype in prototypes])
return np.argmin(distances)4) [EXTRA] Para evaluar LVQ realizaremos lo siguiente:
def classify(x, prototypes):
distances = np.array([euclidean_distance(x, prototype) for prototype in prototypes])
return np.argmin(distances)5) [EXTRA] La visualización del rendimiento de LVQ se realiza a través de:
import matplotlib.pyplot as plt
plt.scatter(class1[:, 0], class1[:, 1], color='blue', label='Clase 1')
plt.scatter(class2[:, 0], class2[:, 1], color='red', label='Clase 2')
plt.scatter(prototypes[:, 0], prototypes[:, 1], color='green', marker='x', s=100, label='Prototipos')
plt.legend()
plt.title("Datos y prototipos de LVQ")
plt.show()